Part the Third: Execution (the Good Kind)
3.1. To die, to sleep (or at least to REST)
3.2. Go Groovy Or Go Home
Let's Give Him to Mongo!
4.1 Treating Vampires Like Objects
Ratpack? Don't you mean The Rat Pack?
5.1. Man oh Man, it's SDKMan
Despair and Denouement
Chapter 1. Part the First: A Warning
With Halloween recently past, it now time, at long last, to talk about my misguided ventures into the Dark Arts, driven by Greed, FOMO [1], and Dreams Of Avarice. I tell this sad tale, not for my own redemption (for there can be none), but in the desperate hope that it may dissuade other poor souls from following my slide into the Depths of Despair.
Accompany me if you wish, for there are nuggets of acquired Wisdom among the rubble of my journey.
Specifically, you may learn something of the subtle arts of RESTful web services, the Ratpack
framework, and even NoSQL databases. But do not stray from the Path, for the Night is Dark and Full of Terrors.
Chapter 2. Part the Second: Temptation
One day, as I was wandered, weak and weary, through my local Barnes and Noble, I encountered a strange phenomenon. There was one, and only one, bookcase labeled “Computer”:
Yet there were three labeled “Teen Paranormal Romance”:
Faced with such evidence of the decline of Western Civilization, I despaired. Before I could fall too far, however, an idea, seductive but profound, shook me to my core. Among the many tomes residing there was the most evil of novels, Twilight, by the sorceress Stephanie Meyer.
I recalled facts made known to be regarding it, namely:
The book was a New York Times #1 Best Seller
It sold over 22 million copies in 2008 alone
It spawned a hellishly boring movie of the same name, featuring vampires that actually sparkled (shudder)
At the time, I was working on my own learned tome, Making Java Groovy.
By contrast:
The New York Times apparently still is not aware of my book
It was nominated for a Jolt award (okay, I did that, but still)
All this despite being the leading Java/Groovy integration book available in the world, among both
dead and undead.
Though it pains me to admit it, a way to take advantage of the situation presented itself. What I needed in order to sell my book was a dose of … Groovy Vampires!
Chapter 3. Part the Third: Execution (the Good Kind)
The dilemma remained: how best to proceed? From whence cometh my vampires?
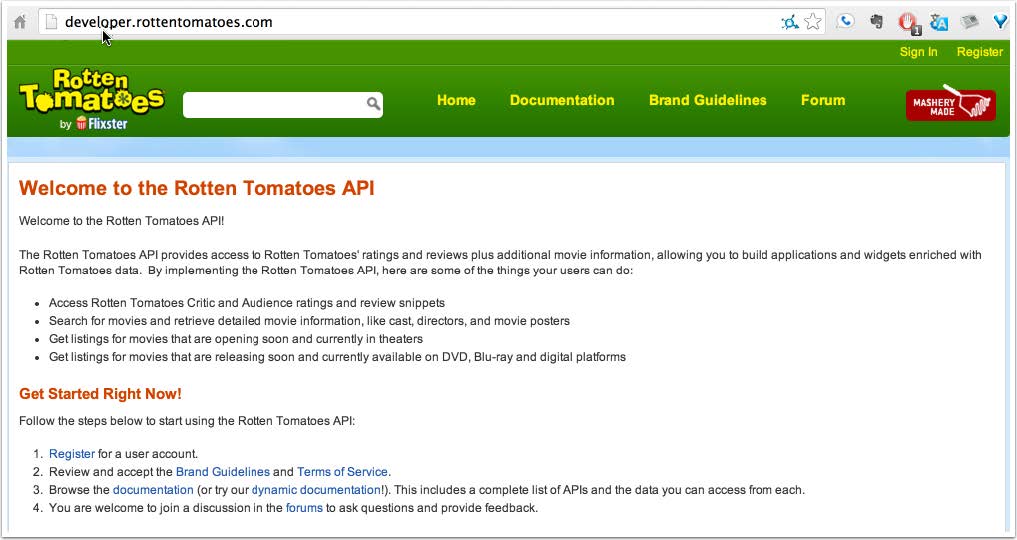
My quest eventually took me to that chronicler of movie reviews, Rotten Tomatoes. The site contains a
RESTful API, accessible from a simple key.
Muttering dark incantations by the light of the full moon while swinging the mouse cable counterclockwise over my head, I was able to secure said secret key.
3.1. To die, to sleep (or at least to REST)
What, pray tell, is a RESTful web service? According to ancient lore [2] and subsequent commentary, declares
Four Principles of REST:
Addressable resources
Every publicly accessible item is assigned an individual URI
Uniform interface
Only the standard HTTP verbs are allowed, which normally means GET, POST, PUT, and DELETE, but sometimes includes PATCH, OPTIONS, or HEAD
Content negotiation
The client requests the form of the response, usually by specifying a MIME-type in the Content-Type HTTP request header
Hypermedia
This often goes by the horrific acronym HATEOAS, or Hypermedia As The Engine Of Application State, which is both unpronounceable and has the word HATE in it
The Rotten Tomatoes API is RESTful, to a degree. It supports GET requests only, which causes some
people to call it a GETful web service [3]. The only MIME-type it supports is JSON, so there's not much content negotiation going on, either, and the URLs themselves include “json” in them.
For example, using the dynamic documentation at https://www.any-api.com/rottentomatoes_com/rottentomatoes_com/docs/API_Description with the query “accelebrate” yields 322 (!) movies, none of which contain the word “accelebrate” in their
titles, but you can't have everything. A portion of the response is shown here:
Example 1. Sample Rotten Tomatoes Output
{
"total": 322,
"movies": [{
"id": "771417417",
"title": "Fare Thee Well: Celebrating 50 Years Of The Grateful Dead",
"year": 2015,
"mpaa_rating": "R",
"runtime": 300,
"release_dates": {
"theater": "2015-07-03"
},
"ratings": {
"critics_score": -1,
"audience_rating": "Upright",
"audience_score": 80
},
"synopsis": "Fathom Events, Peter Shapiro, and Madison House are thrilled to bring Fare Thee Well: Celebrating 50 Years of Grateful Dead to the big screen for an unprecedented LIVE three-night cinema event on July 3, 4, and 5. Each concert will be uniquely different as Hart, Kreutzmann, Lesh and Weir will be joined by renowned musicians Trey Anastasio, Jeff Chimenti, and Bruce Hornsby.",
"posters": {
"thumbnail":
"http://d3biamo577v4eu.cloudfront.net/static/images/redesign/poster_default_thumb.gif",
"profile":
"http://d3biamo577v4eu.cloudfront.net/static/images/redesign/poster_default_thumb.gif",
"detailed":
"http://d3biamo577v4eu.cloudfront.net/static/images/redesign/poster_default_thumb.gif",
"original":
"http://d3biamo577v4eu.cloudfront.net/static/images/redesign/poster_default_thumb.gif"
},
"abridged_cast": [],
"links": {
"self":
"http://api.rottentomatoes.com/api/public/v1.0/movies/771417417.json",
"alternate":
"http://www.rottentomatoes.com/m/fare_thee_well_celebrating_50_years_of_the_grateful_
dead/",
"cast":
"http://api.rottentomatoes.com/api/public/v1.0/movies/771417417/cast.json",
"reviews":
"http://api.rottentomatoes.com/api/public/v1.0/movies/771417417/reviews.json",
"similar":
"http://api.rottentomatoes.com/api/public/v1.0/movies/771417417/similar.json"
}
}, {
// ... 9 more movies on the first page ...
},
}],
"links": {
"self":
"http://api.rottentomatoes.com/api/public/v1.0/movies.json?q=accelebrate&page_limit=10&page=1",
"next":
"http://api.rottentomatoes.com/api/public/v1.0/movies.json?q=accelebrate&page_limit=10&page=2"
},
"link_template":
"http://api.rottentomatoes.com/api/public/v1.0/movies.json?q={searchterm}&page_limit={results-per-page}&page={page-number}"
}
Rotten Tomatoes has their own interpretation of the classic ideas of REST:
Only GET requests are supported
The “content negotiation” is done by embedding the word json in the URLs (see the movies.json parts of the above links)
Hypermedia is used for pagination (see the self and next keys in the links section) and for
additional info, like cast, reviews, and similar
Now that a reliable source of evil has been identified, how best to access it? More, what should be done with the results? Evil don't store easy, you know.
3.2. Go Groovy Or Go Home
As I mentioned above, once upon a few thousand midnights dreary, as I composed, weak and weary, a
quaint and curious tome of forgotten lore entitled Maketh Java Groovy, available from Manning at http://www.manning.com/books/making-java-groovy. After it was released, I managed to blackmail (er, persuade) my local bookstore [4] to stock a couple of copies. Here's what they looked like:
Accessing Rotten Tomatoes using Groovy is easy. Murmuring deep incantations, I conjured this script,
which downloaded the data for Blazing Saddles.
After registering, I stored my API key in a file called rotten_tomatoes_apiKey.txt, which I loaded into the script. The base URL is the movie search request. To build the query string, I needed to “URL encode” the movie titles, because it has a space in it. Groovy doesn't have a URL encoder, but Java does, so I used it here. After composing the full URL, I downloaded the data by transforming the String into an instance of java.net.URL, and then used the Groovy JDK, which added the getText method to URL.
I can then use the links to get the full cast, because if you're going to access Blazing Saddles, you really need to find Mongo, arguably the peak of the Alex Karras oeuvre.
Thus, continuing the above script, I declaimed:
println JsonOutput.prettyPrint(jsonTxt)
def json = new JsonSlurper().parseText(jsonTxt)
// Access the first movie
def movie = json.movies[0]
def allCast =
new JsonSlurper().parseText("${movie.links.cast}?apiKey=$key".toURL().text)
allCast.cast.each { println it }
assert allCast.cast.find { it.characters =~ /Mongo/ }
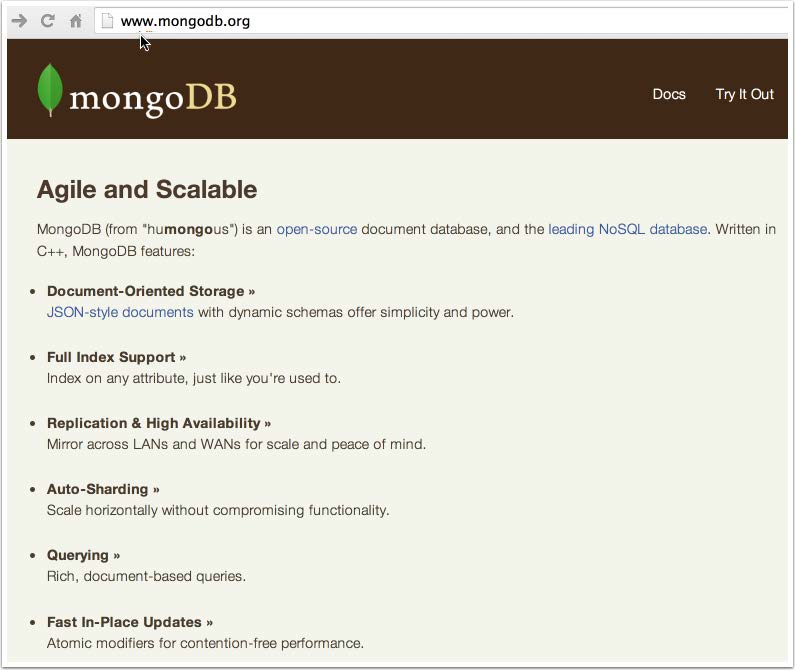
Having thus demonstrated admirable facility at accessing and parsing JSON data, in a flash of insight I realized what do with it. Where better to store Mongo than in MongoDB?
Chapter 4. Let's Give Him to Mongo!
MongoDB (http://www.mongodb.org) is a document-based NoSQL (Not Only SQL) database, specifically designed to hold hierarchical data, like JSON.
MongoDB holds collections of BSON (binary JSON) data. It has a JavaScript API for doing full queries,
and is open source. After setting up the server (called, mongod, no doubt a dark and malevolent god), you have available a command line client called mongo.
Example 3. Starting the MongoDB server
$ mongod
... lots of output ...
2015-12-05T15:45:30.923-0500 I NETWORK [initandlisten] waiting for connections on
port 27017
Example 4. Using the MongoDB client
$ mongo
MongoDB shell version: 3.0.7
> show databases;
movies 0.078GB
> use movies;
switched to db movies
> show collections;
otherMovies
system.indexes
vampireMovies
> db.otherMovies.find();
... lots of JSON output ...
That’s all well and good, but I want to access Mongo from Groovy. At this point I discovered a very
typically Groovy approach — someone took the Java driver for Mongo and wrapped it in Groovy to
make it simpler. The resulting project is called GMongo, located at http://github.com/poiati/gmongo.
If you go to that site and dig into the source, you find a class called com.gmongo.GMongo, a portion of
which is shown below:
Example 5. GMongo with its @Delegate
package com.gmongo
import com.mongodb.Mongo
class GMongo {
@Delegate
Mongo mongo
// ... lots of other stuff ...
}
The GMongo class wraps the Mongo class, which is the base of the Java API, and delegates all method calls to it. The @Delegate annotation takes care of all the delegation methods. Holy AST transformations, Batman! [5].
The GMongo API also overrides the left-shift operator to make it easy to add data to a collection in the database. The following script downloads all the vampire movies from Rotten Tomatoes and adds them to the Mongo DB.
Example 6. Adding vampire movies to the MongoDB database
import groovy.json.*
import com.gmongo.GMongo
GMongo mongo = new GMongo()
def db = mongo.getDB('movies')
db.vampireMovies.drop()
def slurper = new JsonSlurper()
String key = new File('rotten_tomatoes_apiKey.txt').text
String base = "http://api.rottentomatoes.com/api/public/v1.0/movies.json?"
String qs = [apiKey:key, q:'vampire'].collect { it }.join('&')
String url = "$base$qs"
def vampMovies = new JsonSlurper().parseText(url.toURL().text)
db.vampireMovies << vampMovies.movies
def next = vampMovies?.links?.next // Ooh, hypermedia <img src="https://www.accelebrate.com/blog/wp-includes/images/smilies/simple-smile.png" alt=":)" class="wp-smiley" style="height: 1em; max-height: 1em;" />
while (next) {
vampMovies = slurper.parseText("$next&apiKey=$key".toURL().text)
db.vampireMovies << vampMovies.movies
next = vampMovies?.links?.next
}
println db.vampireMovies.find().count()
At last count, that added 326 movies to the database, none of which were Twilight:
Example 7. Any Twilight movies in the DB?
package mjg
import mjg.entities.Movie;
import com.gmongo.GMongo;
GMongo mongo = new GMongo()
def db = mongo.getDB('movies')
// Twilight series: Twilight, New Moon, Eclipse, Breaking Dawn
def results = db.vampireMovies.find().findAll {
it.title =~ /Twilight|Dawn|Eclipse|Moon/
}*.title
println "Twilight series movies in DB: $results"
// Twilight series movies in DB: []
I'm inclined to see that as more of a feature than a bug.
Now that I'm using Groovy to deal with vampires, it's reasonable to move my book into the vampire
section where it belongs.
4.1. Treating Vampires Like Objects
Parsing JSON data with Groovy is easy enough, but evil is seductive. I wanted more.
Those wizards at Google produced a library called Gson, https://github.com/google/gson, which converts Java objects to JSON and back. If Java can do it, Groovy can do it better; so let it be written, so let it be done.
The idea is to create Groovy POGOs (Plain Old Groovy Objects, see my previous blog posts at this site)
whose attribute names match the keys in the JSON structure.
Working from the JSON structure returned by Rotten Tomatoes, the result is something like this:
Example 8. Mapping JSON to POGOs with Gson
import com.google.gson.Gson
import groovy.transform.ToString
@ToString(includeNames = true)
class Movie {
int id
String title
String year
MPAARating mpaa_rating
String runtime
Dates release_dates
Ratings ratings
String synopsis
Posters posters
CastMember[] abridged_cast
MovieLinks links
}
@ToString(includeNames=true)
class CastMember {
String name
long id
List<String> characters = []
}
enum MPAARating {
G, PG, PG_13, R, X, NC_17, Unrated
}
@ToString(includeNames = true)
class MovieLinks {
String self
String alternate
String cast
String clips
String reviews
String similar
}
@ToString(includeNames = true)
class Posters {
String thumbnail
String profile
String detailed
String original
}
@ToString(includeNames = true)
class Ratings {
String critics_rating
Integer critics_score
String audience_rating
Integer audience_score
}
@ToString(includeNames = true)
class Dates {
String theater
String dvd
}
Gson gson = new Gson()
println gson.fromJson(new File("blazing_saddles.json").text, Movie)
// mjg.Movie(id:13581, title:Blazing Saddles, year:1974, mpaa_rating:R, ...)
That works. So I can download JSON data from Rotten Tomatoes, save it in a MongoDB database, retrieve it, and convert it into Groovy POGOs.
Checking on my book strategically placed among the other vampire books, I noticed that it hadn't yet sold. Perhaps, I surmised, customers didn't realize that I did really include vampires in my book, as evidenced by the following image:
I therefore prepared documentation to prove that they were there:
Before adding that, I decided to prepare a web application of my own to serve up vampire movies.
That led me, inexorably, to Ratpack.
Chapter 5. Ratpack? Don't you mean The Rat Pack?
Well, yes and no. In addition to inventing fire, forcing King John to accept the Magna Carta, and
participating in the Diet of Worms [6], the generation before mine had a brief moment when they defined cool. According to this Wikipedia article, the mid-1960s motley crew [7], the Rat Pack
consisted of Frank Sinatra, Dean Martin, Sammy Davis, Jr., Peter Lawford, and Joey Bishop. They
personified that era's unique blend of misogyny and alcoholism that defined popular music before the
Beatles washed them away like, well, a pack of rats.
Many, many years later (circa September of 2007), the Ruby community created a web application
library they called Sinatra in their honor. Not to be outdone, the Groovy community then created an
analogous framework called Ratpack, http://ratpack.io.
Ratpack is great for creating quick and easy web applications, especially if they're based on RESTful
web services. Now that I have all this vampire movie data sitting in a MongoDB database, the next step [8] is to expose it through a web app.
To create a Ratpack app, it's easiest to use an application generator called lazybones, http://github.com/pledbrook/lazybones. Installing lazybones is easily done via SDKMan, an SDK installer based at http://sdkman.io.
I can install SDKman on any operating system that supports a bash shell, and then I can use SDKman to install lazybones, which can then be used to create my Ratpack app.
Let’s reassess, shall we? To build my Ratpack app, I need to:
Install SDKMan
Install lazybones
Run the lazybones installer to create a Ratpack app
Create a class to pull vampire movie data out of MongoDB and serve it up through the app
Lazybones can now be used to create a Ratpack app via:
$ lazybones create ratpack HellMouth111
If you're going to serve up vampires, you might as well provide a hellmouth from which they can emerge, because, frankly, it's hard to believe I've written this much about vampires without making one Buffy the Vampire Slayer reference.
(Of course, I haven't made a Firefly reference, either, or a Babylon 5 one, but I'll probably find a way to shoehorn one in somewhere. Like in this paragraph, for instance.)
The current version of Ratpack is 1.1.1, thus the 111 at the end of the application name, unless you
want to pretend they're exclamation points in l33t-speak [9].
The generated Ratpack app includes a useful README.md file.
Example 10. The README.md file in the generated Ratpack app
Ratpack project template
You have just created a basic Groovy Ratpack application. It doesn't do much at this point, but we have set you up with a standard project structure, a Guice back Registry, simple home page, and Spock for writing tests (because you'd be mad not to use it).
In this project you get:
* A Gradle build file with pre-built Gradle wrapper
* A tiny home page at src/ratpack/templates/index.html (it's a template)
* A routing file at src/ratpack/Ratpack.groovy
* Reloading enabled in build.gradle
* A standard project structure:
<proj>
|
+- src
|
+- ratpack
| |
| +- Ratpack.groovy
| +- ratpack.properties
| +- public // Static assets in here
| |
| +- images
| +- lib
| +- scripts
| +- styles
|
+- main
| |
| +- groovy
|
+- // App classes in here!
|
+- test
|
+- groovy
|
+- // Spock tests in here!
That's it! You can start the basic app with
./gradlew run
but it's up to you to add the bells, whistles, and meat of the application.
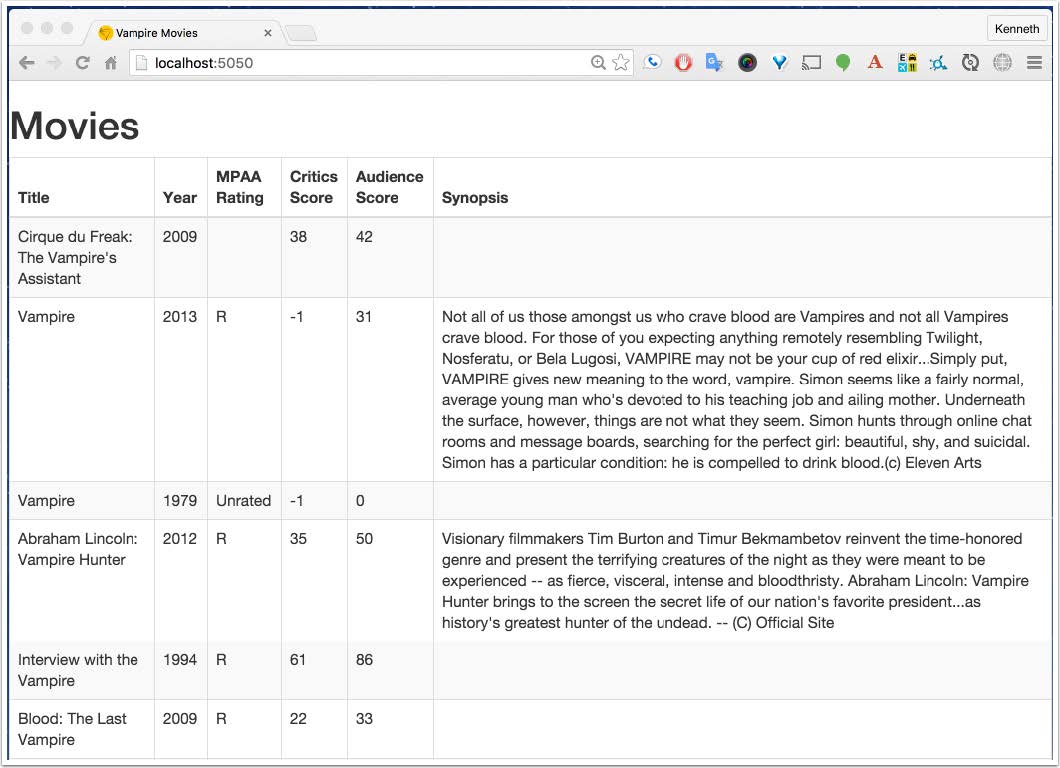
To serve up my vampire movies, I want methods to find all movies with a given string in the title, find a given movie by title, and find a random movie. To that end, here's my VampireServer groovy class.
Example 11. VampireServer.groovy
package com.kousenit
import com.gmongo.GMongo
import com.google.gson.Gson
import com.mongodb.DB
@Singleton ?
class VampireServer {
Gson gson = new Gson() ?
GMongo mongo = new GMongo() ?
DB db = mongo.getDB('movies')
List<Movie> findAllByTitle(String title) { ?
def cursor = null
if (title) {
cursor = db.vampireMovies.find(title: ~/.*${title}.*/)
} else {
cursor = db.vampireMovies.find()
}
cursor?.collect {
gson.fromJson(it.toString(), Movie)
}
}
Movie findByTitle(String title) { ?
gson.fromJson(db.vampireMovies.findOne(title: title).toString(), Movie)
}
Movie getRandom() { ?
List movies = db.vampireMovies.find().collect {
gson.fromJson(it.toString(), Movie)
}
Collections.shuffle(movies)
movies[0]
}
}
? Groovy AST transformation to make the VampireServer a singleton
? Using Google's Gson library to translate from JSON to Groovy and back
? Remember the GMongo driver from several sections ago? Yeah, me neither
? Public methods for retrieving vampire movies
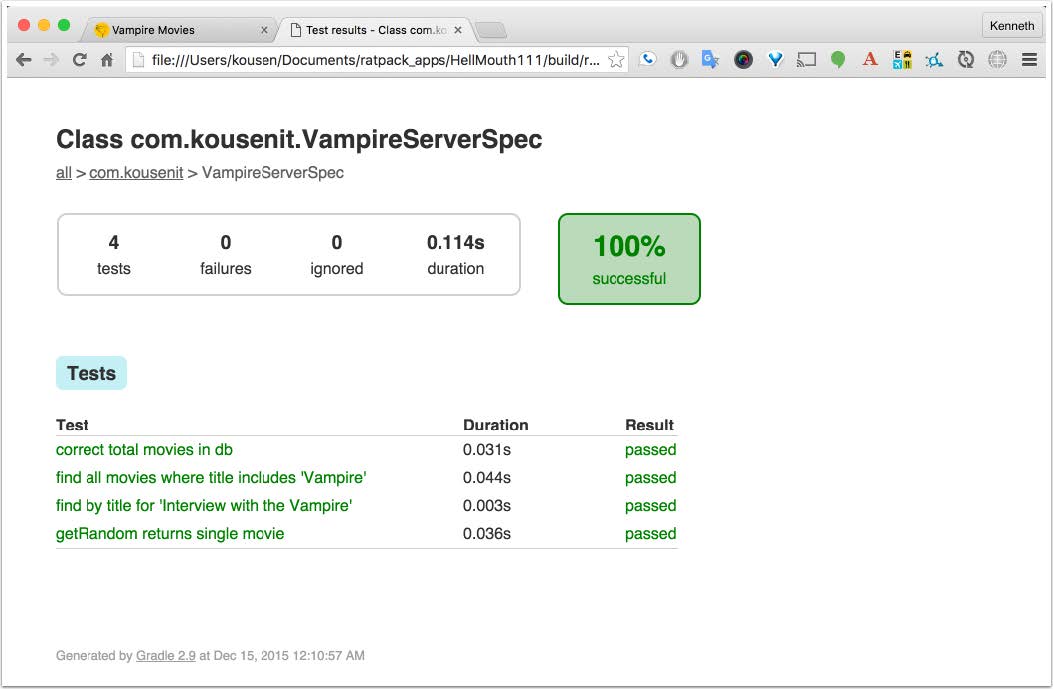
The GMongo driver is used to retrieve JSON data from the MongoDB and translate it into instances of the Movie class. This clearly has to be tested, so here's my VampireServerSpec, a Spock test for its methods.
Example 12. VampireServerSpec.groovy
package com.kousenit
import spock.lang.Shared
import spock.lang.Specification
class VampireServerSpec extends Specification {
@Shared VampireServer server = VampireServer.instance
def "find by title for 'Interview with the Vampire'"() {
when:
Movie m = server.findByTitle('Interview with the Vampire')
then:
m
m.year == '1994'
m.mpaa_rating == MPAARating.R
}
def "find all movies where title includes 'Vampire'"() {
when:
Collection movies = server.findAllByTitle('Vampire')
then:
movies.every { Movie m ->
m.title.contains('Vampire')
}
}
def 'correct total movies in db'() {
expect:
server.findAllByTitle().size() == 326
}
def 'getRandom returns single movie'() {
when:
Movie m = server.random
then:
m
}
}
The test demonstrates that if you search for “Interview with the Vampire”, the resulting movie is not
null, has the right year, and the correct MPAA rating, despite the fact I've never seen it. I'm also able to check that if I search for movies with the word “Vampire” in them, then all the resulting titles include that word. I then verify that there are 326 movies in the database, and that when I retrieve a random movie, it's not null.
So far, so good, but that just proves I can query the database and convert the results to the correct type. Now I want to serve them up through an app.
Here is the script Ratpack.groovy, from the root directory.
Example 13. Ratpack.groovy
import com.kousenit.Movie
import com.kousenit.VampireServer
import ratpack.groovy.template.MarkupTemplateModule
import static ratpack.groovy.Groovy.groovyMarkupTemplate
import static ratpack.groovy.Groovy.ratpack
VampireServer server = VampireServer.instance
ratpack {
bindings {
module MarkupTemplateModule
}
handlers {
get { ?
List<Movie> movies = server.findAllByTitle()
render groovyMarkupTemplate("index.gtpl", movies: movies)
}
get('title/:title') { ?
List<Movie> movies = server.findAllByTitle(pathTokens.title)
render groovyMarkupTemplate("index.gtpl", movies: movies)
}
get('movie') { ?
Movie movie = server.findByTitle(
URLDecoder.decode(request.queryParams.title, 'UTF-8'))
render groovyMarkupTemplate('show.gtpl', movie: movie)
}
files { dir "public" }
}
}
? Respond to HTTP GET request at /
? Respond to HTTP GET requests at /title with a title path token
? Respond to HTTP GET requests at /movie with a title parameter
The server responds to HTTP GET requests only, though this could easily be generalized. If you send a
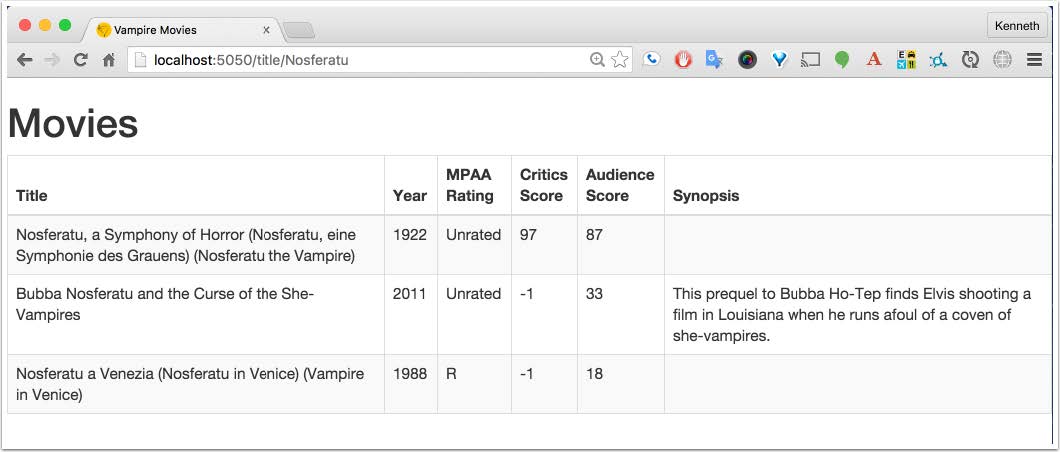
request to the root URL, all the movies are returned to a template for rendering. If the URL includes title/ and a path token, the server searches for movies with that string in the title. Finally, if you access the URL containing movie, the server uses a query parameter called title to find all matching movies.
This too needs to be tested, but the situation is a bit more complicated because of the templates. If the server simply returned JSON data, then it could be parsed and validated. Instead, two Groovy
templates are used to render the output. The first is index.gtpl:
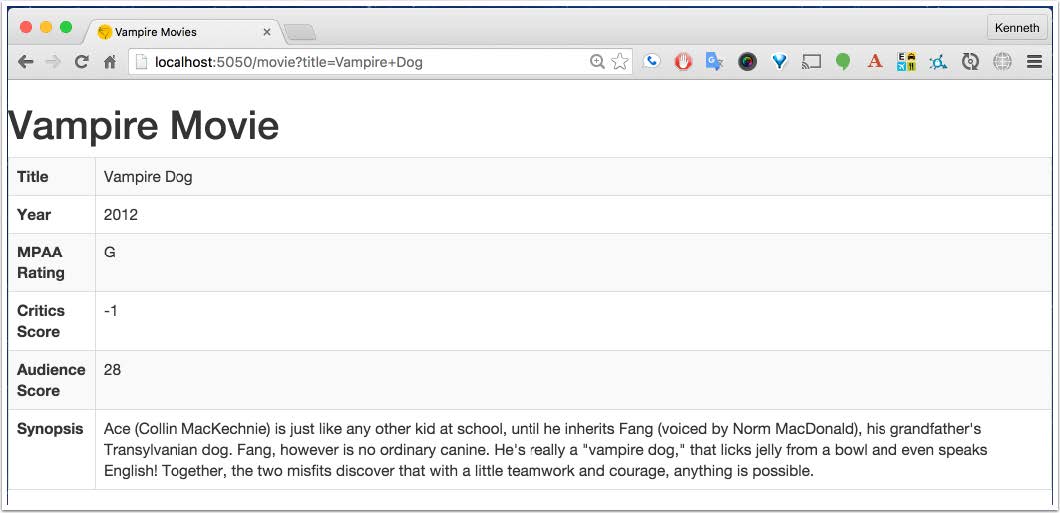
An example is given by searching for “Vampire Dog”.
Finally, searching using the HTTP template is done via a query:
Testing this requires parsing the resulting HTML. Like so much of this blog post, that way lies madness, unless you use a good library. The JSoup library, http://jsoup.org/, is one such library.
The resulting test looks like:
Example 16. Integration testing the ratpack app
package com.kousenit
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import ratpack.groovy.test.GroovyRatpackMainApplicationUnderTest
import ratpack.test.ServerBackedApplicationUnderTest
import ratpack.test.http.TestHttpClient
import spock.lang.Specification
class ServerIntegrationSpec extends Specification {
ServerBackedApplicationUnderTest aut =
new GroovyRatpackMainApplicationUnderTest()
@Delegate
TestHttpClient client = testHttpClient(aut)
def "GET(/) with no title returns all movies"() {
when:
get('/')
then: 'table has one header row and 327 movie rows'
response.body.text.findAll(/<tr>/).size() == 327
response.statusCode == 200
}
def 'GET(/?title=...) returns all movies that include that title'() {
when:
get('/?title=Vampire')
then:
Document doc = Jsoup.parse(response.body.text)
doc.select('tr > td:eq(0)').every {
it.toString().toLowerCase().contains('vampir')
}
response.statusCode == 200
}
def "GET(/movie?title=...) returns that single movie"() {
when:
String encodedTitle =
URLEncoder.encode('Interview with the Vampire', 'UTF-8')
get("movie?title=$encodedTitle")
then:
response.body.text.contains 'Interview with the Vampire'
response.body.text.contains '1994'
response.statusCode == 200
}
def 'GET(/title/:title) returns all movies with that title'() {
when:
get("title/Vampire")
then:
Document doc = Jsoup.parse(response.body.text)
doc.select('tr > td:eq(0)').every {
it.toString().toLowerCase().contains('vampir')
}
response.statusCode == 200
}
def cleanup() {
aut.stop()
}
}
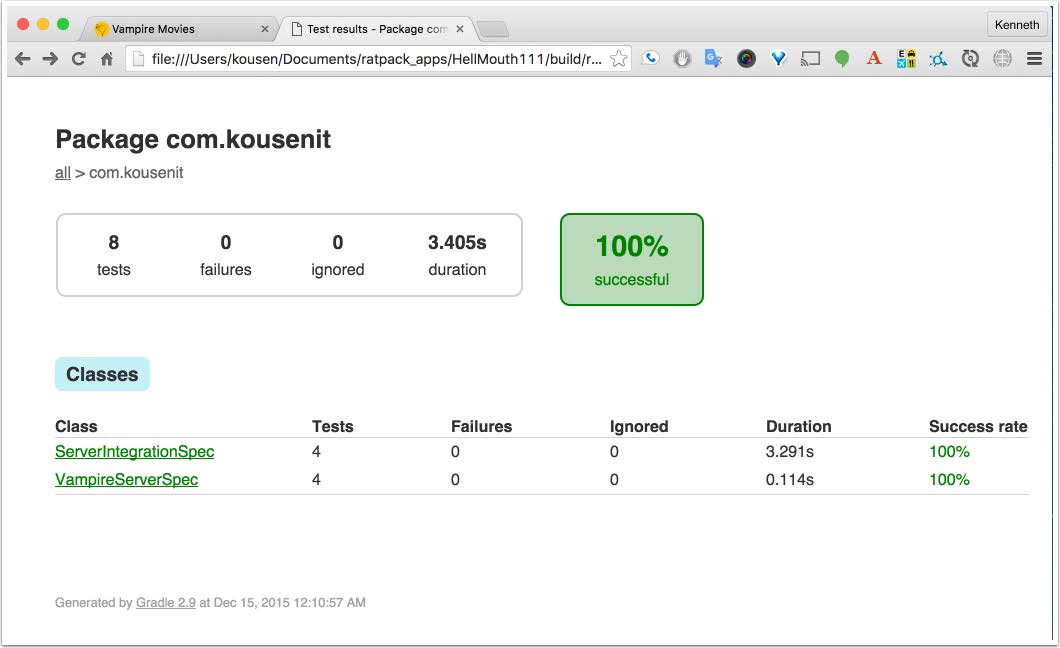
One of the nice features of Ratpack is that you can execute an integration test like that, and the system will start a test server, deploy the app, run all the tests, generate a test report, and shut down the server.
Everything works as advertised.
Chapter 6. Despair and Denouement
So if everything works, why the dire warnings? Why the subtext of sadness and despair?
As I mentioned, I went into my local Barnes and Noble and planted my book in the Teen Paranormal Romance section. I even prepared the Post-It note showing exactly where to find the Groovy Vampires in my book. But before I could place the note on the cover, I had to go on my normal travels.
When I returned and looked for the book, it was gone! Such joy! Such rapture! Someone must have actually bought the book!
I went to the information desk with just the right blend of pride and humility and asked if the book had actually sold.
Sadly, it was not to be. Somebody had moved it, and it was nowhere to be found.
It seems, tragically, that the target audience for teen paranormal romances does not, in fact, significantly overlap the audience for Java/Groovy integration books. Who could have possibly
expected that?
Perhaps I can salvage the situation. Maybe I just need a different approach, with a good subtitle.
Maybe this is the way to go:
Even if true, that might be too negative. Here's an alternative:
If that doesn't work, there's one other possibility:
Only time will tell.
——————————– 1. Fear Of Missing Out, which powers much of Silicon Valley, if not the whole IT world 2. Roy Fielding's Ph.D. thesis, entitled “Architectural Styles and the Design of Network-based Software Architectures”, found at https://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm 3. Taking this to its logical conclusion: if it's also stateless, does that make it a ForGETful web service? (Insert evil laugh here) 4. Remember bookstores? They were like amazon.com, but in realspace, with coffee, toys, and tons of non-book merchandise. 5. Now I'm not just mixing metaphors, I'm blending them into a puree. 6. Not at all what it sounds like. See https://en.wikipedia.org/wiki/Diet_of_Worms for details. Oh, and “the Holy Roman Empire was neither Holy, nor Roman, nor an Empire. Discuss.” 7. Not Mötley Crüe, http://www.motley.com/; wow, this paragraph has been really random, hasn't it? 8. The next step to what? Seriously, where am I going with all this? Frankly, if I knew, I'd tell you. That's what you get when you mess with evil. Or Texas, which is not a good state with which to mess. 9. https://en.wikipedia.org/wiki/Leet
Ken Kousen is an independent consultant and trainer specializing in Spring, Hibernate, Groovy, and Grails. He is a regular speaker at conferences and the Author of "Modern Java Recipes" (O'Reilly Media), "Gradle Recipes for Android" (O'Reilly Media), and "Making Java Groovy" (Manning).