In Part 1 and Part 2 of this series, we discussed best practices for JavaScript and how to properly work with data and React components. In this post, we will explore best practices for React component trees and managing application state with MobX.
Best Practice #5 – Structuring a Component Tree
The React library provides three kinds of components: normal components, pure components, and stateless functions. Each has its own costs and benefits.
What Are Normal Components?
Normal components are created by extending React.Component and are general purpose React components providing access to the full component API. They support the use of state and lifecycle functions, and by default, perform no change detection. They always opt to re-render the Virtual DOM.
React maintains a Virtual DOM in memory which is nothing more than an object tree of React elements. The changes to the Virtual DOM in memory dictate the optimal set of changes which are applied to the real DOM of the web browser. In the final set, real DOM changes are the updates the user sees. For the right changes to be made, the real DOM must be in sync with the Virtual DOM, or the rendered changes will not be correct. Choosing one component kind or another to improve re-rendering performance only impacts the re-rendering of the Virtual DOM. The rendering of the real DOM is always optimized through a process known as Reconciliation.
What Are Pure Components?
Pure Components support component state and lifecycle functions as well. However, they have a special version of the shouldComponentUpdate function that does a shallow comparison of current props and new props to see if anything has changed.
shouldComponentUpdate(nextProps, nextState) {
// build a set of all property names on the existing props and next props
const propsPropertyNames = new Set(Object.keys(this.props), Object.keys(nextProps))
// iterate over the whole set of props
for (let propName of propsPropertyNames) {
// if any of them are not the same, then return true and update
// observe only object references would be compares for props which
// which point to objects
if (this.props[propName] !== nextProps[propName]) {
return true;
}
}
// repeat the same process for state
const statePropertyNames = new Set(Object.keys(this.state), Object.keys(nextState))
for (let propName of Object.keys(statePropertyNames)) {
if (this.state[propName] !== nextState[propName]) {
return true;
}
}
// no changes do not re-render
return false;
}
If nothing has changed, then Pure Components do not re-render. For this to work, all objects passed in as props must have new object references for the shallow comparison, otherwise the change will not be detected and a Pure Component will not re-render. Using Pure Components can improve the performance of the application, but they do require discipline on the part of the developer to make changes immutably to objects. Making immutable changes is covered in detail in the first post of this series.
What Are Stateless Function Components?
The final type of component is the stateless function. Stateless function components do not support state or lifecycle functions. Because there are no lifecycle functions associated with this type of component, they will always re-render. The benefit of stateless functions is that they are easy to code and maintain. The lack of both lifecycle methods and component instantiation also makes them very fast.
Container Components and Presentational Components
In addition to the three kinds of components, there are two kinds of conceptual components that have emerged over time: container components and presentational components.
Container components connect a component tree to the application environment and display very little or no UI content. Presentational components are ignorant of the application environment and focus on displaying UI content only. Container components are tightly-coupled to the specific application, while presentational components are highly reusable throughout an application and across many applications.
Typically, normal React components are used to implement container components because life-cycle methods are critical to connecting the component tree to the application environment. Presentational components are typically implemented as pure components or stateless functions. However, there are always exceptions to these general rules.
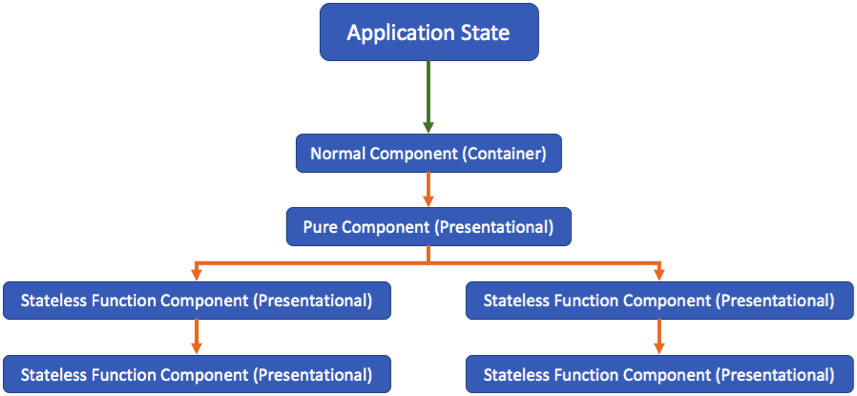
A good pattern to follow is to build a component tree with the following structure:
The normal (container) component will connect to the application environment, which is usually the application's state container. The pure component will check to see if new props are available using the shallow comparison. If new props are indeed available, then it will re-draw the whole presentational tree. The benefits of rendering only when needed (pure components) and faster rendering (stateless functions) are gained by such a structure.
Also, it should be noted that the entire UI component tree of an application will generally have many container components, each with a presentational tree under them. The depth of the presentational tree should be kept as shallow as possible. Often, deep presentational trees reflect an improper organization of components.
React 16 has improved error-handling for components. Depending upon the error handling needs of the component tree, a parent component can handle the error thrown by a child component using the componentDidCatch lifecycle function. Because this does require the lifecycle functions, a stateless function component cannot be used. Such logic could be implemented in the pure component or container component described in the tree diagram above. Handling errors is critical to any application, especially a UI application where mishandling has an immediate impact on the user experience. Each container component tree should handle the errors generated by the presentational components within the tree.
Best Practice #6 – Application State vs. Component State
The concept of state within UIs can be controversial and confusing. Part of the confusion lies in the fact that the single word "state" has come to describe many kinds of data that is different, but related. Roughly speaking, state is the data which changes in an application as the application executes. State can include the data managed by the application. It also can include user session data, such as a search string or which column is being sorted on. Some state data can be persistently stored in a database (or other storage mechanism) or it can exist only while the application is executing.
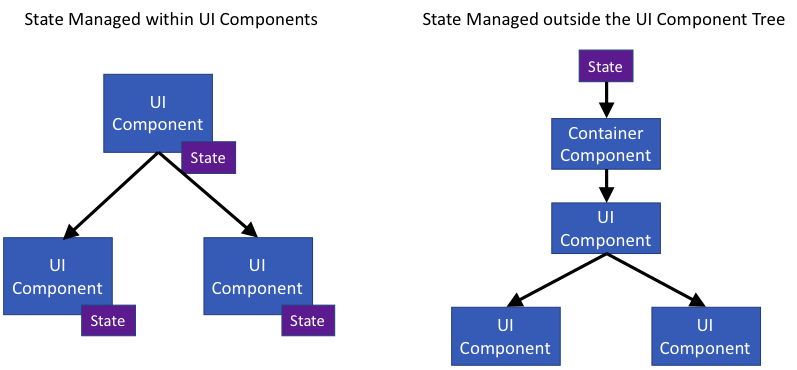
All applications have state, and all applications must follow a scheme to storing their state. Applications previously stored their state in many places throughout the application, usually within their UI elements. However, this distribution of state management throughout the application resulted in data flows which were hard to follow. State data would become inconsistent throughout the UI. In recent years, a new approach has been developed and used with great success.
This new approach removes the application's state from the UI elements (the component tree in the case of React) and is placed in one or more stores. Two of the most popular state-management libraries are Redux and MobX. They use one store and multiple stores, respectively. The stores are then connected to the component tree via a container component (described earlier). Moving the state out of the UI ensures a state which is easily managed, easy to update, and easy to keep consistent. Also, the management of the state is not tightly-coupled to the implementation of the UI, easing the maintenance and extending the application.
Overall, state containers such as MobX have been very helpful in improving the management of data within a UI application. There is a problem though—not all state is really application state. For example, the React library takes a unique approach to entering data into input, textarea, and select form controls. React captures the event of entering data into a form control, updates the local component state with the entered data, and then efficiently re-renders the form controls with the new local state data. This process happens on every data entry event (such as a keystroke, for example). When using this configuration, the form control is known as a controlled component. With an understanding of React's peculiar approach to collecting form data, let's return to the original issue of managing state.
The component requires state, however, as explained earlier, state should be managed outside of the component tree. The question is this: should the component manage this very local state of typing data into a form OR should the component allow the state container to manage data entry events, such as typing into an input field? Depending on the developer you ask, the blog post you read, etc., you will get different answers. My recommendation is that all state be managed by a state container such as MobX, except for form data that does not impact any other part of the application. Because React refers to something as state, it does not necessarily make it application state. It's important to consider how the data is being used, not so much the various labels which are applied to it by a library or framework.
Let's explore a simple example related to the form data. If the purpose of state is to merely capture data from an input element on each keystroke, then that kind of state is not application state. Instead, it is just an internal mechanism used by React to capture data so that the virtual DOM and real DOM are kept in sync. This should not be stored in MobX (or any kind of external state container).
Now let's expand the role of the input. Let's say the input field produces an autocomplete drop down as the user types (think of a search engine with search terms suggested in real time). That would impact application state, as the search terms must be queried from a server based on the user entry at each keystroke, and then displayed so they can be selected. In this case, the user entry for the single input field should be tracked on the application state with MobX.
The key is not to decide the role of data based upon labels applied by libraries; rather, they key is to understand the nature of data and its relationship to the application. By understanding the concept and principle, the right decisions will be made about how to manage data regardless of the library or framework being used.
Best Practice #7 – Computed Properties
One of the fundamental principles of MobX (and any state container) is keeping state as small as possible and deriving as much as possible from the state. The same recommendation could be said of Redux. Even React recommends this when working with state within components. This makes a lot of sense as the management of state adds complexity to the application as described earlier. The challenge of this approach is that developers instinctively do not like to re-calculate values which have not changed. Instead, they desire to store (or cache) them for re-use in the future.
JavaScript is single-thread, and within a web browser, JavaScript shares its thread with the UI engine. When JavaScript is executing a task, the web browser cannot update the UI and vice versa. When JavaScript executes a computationally-intensive task, the browser can appear to freeze up, as the UI engine cannot respond to user interactions because JavaScript is using all the CPU time executing code. Therefore, the problem with producing all that can be derived means more computationally-intensive work. The obvious (but incorrect) solution, is to store these derived values on state to prevent re-calculation. Doing this expands the state and results in the problems described earlier. Within MobX, the solution is the use of Computed Properties.
Computed properties are a special kind of property that updates itself when its data dependencies have been updated and the property is accessed. MobX's special property access tracking change detection system allows computed properties to only update themselves when their state dependencies have changed. The computed value is then stored and re-used when requested. When the state changes, the computed properties are not updated automatically, instead their re-calculation is deferred until the computed property is accessed again.
export class CarStore {
@observable
cars = [];
@observable
sortFieldName = 'id';
@observable filterFieldName = '';
@observable filterFieldValue = '';
// computed properties observe the properties above through
// property accessor tracking
@computed
get filteredCars() {
if (this.filterFieldName === '') {
return this.cars;
}
return this.cars.filter( car =>
String(car[this.filterFieldName]).includes(String(this.filterFieldValue)) );
}
@computed
get sortedCars() {
return this.filteredCars.sort( (a, b) =>
a[this.sortFieldName] > b[this.sortFieldName] );
}
// … omitted …
}
The re-using of computed values in the same function is called memoization. Memoization is caching the results of a function based on the arguments passed to it. Memoization is not application state as it is tied only to the function, and the stored value can be disposed at any time. The difference between MobX's Computed Properties and traditional function memoization is that instead of function arguments being used as a basis of caching, the property access tracking is used. Please visit https://lodash.com/docs#memoize if you are interested in learning more about function memorization. If you are not using MobX, memoization can be very helpful in caching derived results in general with React applications.
Conclusion
Beyond the mastering of language features and APIs, the usage of JavaScript and libraries such as React and MobX requires following key principles to ensure applications are performant, scalable, maintainable, and ultimately accomplish their purposes. Many of the principles require the developer to make good choices that cannot be enforced or verified by JavaScript and its many coding libraries and frameworks.
When used correctly, JavaScript rocks. When used incorrectly, JavaScript is a source of great frustration. The best practices in this series of posts do not represent all best practices nor do they represent the perfect solution in every case. But these best practices can reduce the number and severity of bugs in your applications while improving performance and maintainability. Do you have any best practices from your experiences? Do you disagree with any of the practices listed in this blog post? If so, tell us in your comments below.
Accelebrate offers private React/Redux training for groups and instructor-led online JavaScript classes for individuals.
Eric is a professional software developer specializing in HTML, CSS, and JavaScript technologies. He has been developing software and delivering training classes for nearly 19 years. He holds the MCSD Certification for ASP.Net Web Applications, and is a Microsoft Certified Trainer.